
Realization of H.26L 4 × 4 point integer transformation on TM1300
Abstract: H.26L is the next-generation video coding standard. Its codeability exceeds all existing standards, including H.263 + and MPEG-4 (SP). This article analyzes a variety of new coding features introduced by H.26L, focuses on 4 × 4 point integer transformation, and proposes a fast transformation algorithm implemented on TM1300.
introduction
H.26L is the next generation video coding standard. Initially, H.26L was developed by the ITU-T VCEG group. In November 2001, MPEG and VCEG jointly established the JVT group to participate in the formulation of H.26L. Because of the addition of MPEG, H.26L will be included in the tenth part of MPEG-4. Because the H.26L standard is still in the process of formulation, this article temporarily takes the test model TML8 provided by JVT as a reference.
The basic coding framework of H.26L source coding is similar to the current popular video coding standard, and uses a hybrid coding technique combining transform coding and predictive coding. Its excellent performance mainly comes from the introduction of new encoding features: 4 × 4 point integer transform, entropy encoding using UVLC, running vectors with 1/4 to 1/8 pixel accuracy, motion estimation with multiple block sizes, and so on. These new coding techniques improve compression performance and fault tolerance from different sides. Especially the 4 × 4 point integer transform is unique among all video compression protocols.
Although the H.26L standard is still being formulated, in the preliminary test, its coding performance surpassed all existing standards, including H.263 + and MPEG-4 (Simple profile). These test results show that under the same objective video quality, H.26L can save 20% -50% bit rate than H.263 + and 50% bit rate than MPEG-4 (SP). As the next-generation video coding standard, H.26L demonstrates its huge development prospects.
1 H.26L 4 × 4 point integer transform
1.1 Introduction to Transformation
In H.26L coding technology, the 4 × 4 point integer transform can be regarded as an integer version of the DCT transform, which mainly removes the spatial correlation of the image and has the same properties as the 4 × 4 point DCT transform. Consider the one-dimensional integer transformation first: Let a, b, c, and d be the four points to be transformed, and A, B, C, and D are the corresponding four transformation coefficients. , Positive transformation at point d:
A = 13a + 13b + 13c + 13d
B = 17a + 7b-7c-17d
C = 13a-13b-13c + 13d
D = 7a-17b + 17c-7d
The inverse transformation formula is as follows:
a '= 13A + 17B + 13C + 7D
b '= 13A + 7B-13C-17D
c '= 13A-7B-13C + 17D
d '= 13A-17B + 13C-7D
The relationship between a and a 'is a' = 676a. That is to say, after the inverse transformation, the normalization operation is also needed to make the forward transformation and the transformation scale consistent.
The transform kernel of the same two-dimensional 4 × 4 integer transform is separable. The separate transformation reduces the computational complexity from O (N4) to O (N3).
1.2 Comparison with 8 × 8 point DCT transform
Compared with traditional DCT transform, H.26L adopts 4 × 4 point integer transform to bring the following advantages to video coding:
①Helps to reduce block spots and ring spots, and improve the image quality. Due to the quantization of the transform coefficients, resulting in the loss of high-frequency coefficients, there will be block shifts and ring shifts in the restored image. In H.26L, a smaller 4 × 4 point transform is used, which can effectively suppress block spots and ring spots.
â‘¡Integer transform reduces the accumulated error. The traditional accumulated error comes from two aspects: the error caused by the mismatch between the forward transform and the inverse transform and the error caused by the quantization. In order to achieve the purpose of compression, the second error is inevitable. However, since H.26L uses precise integer transform, the forward transform and inverse transform will not produce errors, which effectively reduces the accumulated error.
â‘¢The calculation speed is fast. Because the transformation formula used by H.26L is a simple integer equation, that is to say, calculations are based on integers, not floating-point numbers, so it reduces the amount of calculation for a single transformation and is also beneficial to the use of fixed-point DSP.
2 Implementation in TM1300
TM1300 is a 32-bit ultra-high performance multimedia processor. Its core processor uses the VLIW ultra-long instruction word structure, which can perform 5 operations simultaneously in each clock cycle; it supports highly parallel custom operations, which can greatly speed up the special operations common in digital signal processing and multimedia applications. Performance, and the use of custom operations is similar to C language function calls, which facilitates the design of the program.
In this paper, according to the characteristics of 4 × 4 point integer conversion and the characteristics of TM1300's custom operation instructions, the following adjustments are made to integer conversion: first perform row conversion, then do column conversion. Because the result of the row conversion will not exceed the 16-bit representation range, before the column conversion, the data is re-merged and the column conversion is performed. This is based on the following two considerations.
First, because the video input data is an unsigned byte type, and TM1300 is a 32-bit processor, accessing memory in word units can improve the efficiency of access. The data of the current 4 × 4 data block (pointer is P1) and the reference frame 4 × 4 data block (pointer is P2) are organized as follows. The point to be transformed is the difference between the value of the current data block and the corresponding value of the reference frame data block.
P1: cal, cb1, cc1, cd1 P2: ra1, rb1, rc1, rd1
ca2, cb2, cc2, cd2 ra2, rb2, rc2, rd2
ca3, cb3, cc3, cd3 ra3, rb3, rc3, rd3
ca4, cb4, cc4, cd4 ra4, rb4, rc4, rd4
Second, you can use the custom operation of 8-bit multiplication / accumulation. One operation can complete four 8-bit multiplication / accumulation, and a machine cycle (CLK) can perform up to 5 operations. Compared with non-customized multiplication / accumulation, it reduces the number of operations and improves the parallelism of program execution. 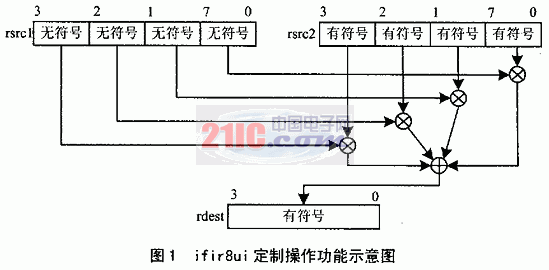
Figure 1 is a schematic diagram of ifir8ui customized operation functions.
3 Experimental results
The fast algorithm of 4 × 4 integer transform based on TM1300 proposed in this paper uses parallel computing technology to greatly reduce the amount of calculation. Experiments show that to perform a 4 × 4 point integer transform, it takes 80 machine cycles to directly use multiplication and addition operations, and the improved algorithm requires only 28 machine cycles; while using TM1300 to perform an 8 × 8 point fixed-point DCT transform requires 180 machine cycles are also significantly greater than four 4 × 4 point integer transformation times. In terms of transformation, H.264's transformation coding operation complexity is less than other encoding methods.

Follow WeChat

Download Audiophile APP

Follow the audiophile class
related suggestion
'+ data.data.username +' '; dom + ='
The single phase filters have a good attenuation performance at frequency range 150KHz~30MHz.
They have a compact structure and high performance-cost ratio.
The Single Phase Noise Filter is easy to install, which is also safe and reliable.
FT110 and FT111 series sihgle phase EMI Filters are one-stage common mode ones with almost the same filtering effect, only slight difference according to different current.High voltage versions above 380VAC are also available.
Rated current: 0.5A~300A
Various connection types: wire, solder lug, stud, terminal blocks, etc
Typical Applications: Electrical & electronic equipment, Household appliance, Datacom equipment, Consumer goods, Medical devices, Office automation equipment

Phase Filter,Single Phase Filter,Single Phase Noise Filter,Single Phase EMI Filter
Jinan Filtemc Electronic Equipment Co., Ltd. , https://www.chinaemifilter.com