
The effectiveness of each error measure will be discussed from the perspective of objectives and issues
The quality and merits of the model are all relative judgments based on certain angles. In this article, we will discuss the effectiveness of each error measure from the perspective of goals and problems. When someone tells you that "China is the best country," the first question you ask is definitely what the basis of this statement is. We assess whether we compare countries based on the state of the economy, the level of education, or their health facilities. What? Similarly, each machine learning model uses different data sets to solve the problem of different targets in a targeted manner. Therefore, before choosing the appropriate metrics, you must have a deep understanding of the context.
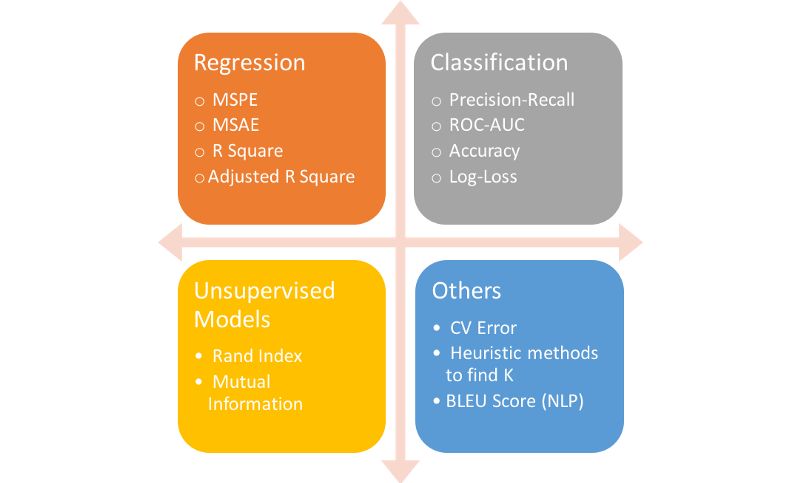
Graphs Common metrics for various machine learning models
Regression metrics
Most blogs focus more on model accuracy, recall, AUC (area under curve, area under ROC curve), and other classification indicators. We would like to make a slight change here. Let us explore a variety of indicators, including those used in regression questions. MAE and RMSE are the two most common metrics for continuous variables.
First, we look at the most popular RMSE, the full name is Root Mean Square Error, which is the root mean squared error, which represents the sample standard deviation of the difference between the predicted value and the observed value (called the residual). In mathematics, it is calculated using the following formula:
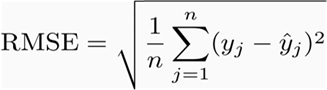
Followed by MAE, the full name is Mean Absolute Error, the average absolute error, which represents the average of the absolute error between the predicted value and the observed value. MAE is a linear fraction. All individual differences have equal weights on the average. For example, the absolute error between 10 and 0 is twice the absolute error between 5 and 0. However, this is not the same for RMSE and will be discussed in further detail later. Mathematically, MAE is calculated using the following formula:
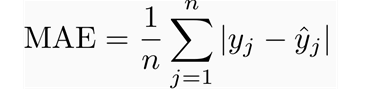
So which one should you choose? Why did you choose this?
First of all, it is easy to understand and interpret MAE, because it is to calculate the average of residuals directly, and RMSE will punish more for high differences than MAE. Let us understand through two examples:
Case 1: Real value = [2,4,6,8], predictive value = [4,6,8,10]
Case 2: Real value = [2,4,6,8], predictive value = [4,6,8,12]
Case 1 MAE = 2.0, RMSE = 2.0
Case 2 MAE = 2.5, RMSE = 2.65
From the above example, we can find that RMSE punishes the last prediction value more than MAE. In general, RMSE is greater than or equal to MAE. The only case that is equal to MAE is that all the residuals are equal or equal to zero*. If all the residuals between the predicted value and the true value in Case 1 are 2, then the MAE and RMSE values ​​are equal.
> Although RMSE is more complex and tends to higher errors, it is still the default metric for many models because the RMSE is used to define the loss function as *differentiable* and easier to perform mathematical operations.
Although this sounds unsatisfactory, it is indeed the reason why it is very popular. I will explain the above logic from a mathematical point of view. First, let's build a simple univariate linear model: y = mx + b. In this problem, we want to find the best "m" and "b", and the data (x, y) is known. If we use the RMSE to define the loss function (J): then we can easily find the partial derivative of J on m and b and use this to update m and b (this is how the gradient descent works, not much here Explain it)
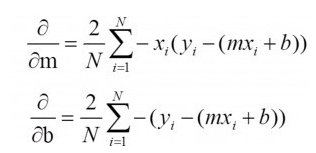
The above equation is easy to solve but not for MAE. However, if you need a metric to compare two models from an intuitive interpretation point of view, then I think MAE will be a better choice. It is worth noting that the units of RMSE and MAE are the same as y but not R Square. In addition, both RMSE and MAE range from 0 to infinity.
> One important difference between MAE and RMSE needs to be mentioned here. Minimizing the square error of a set of numbers will get its mean value, while minimizing the absolute error will get the median value, which is why MAE ratio RMSE vs. outliers The more effective reason.
R Squared, R2 Correction R Squared
R2 and correction R2 are often used to illustrate how well the selected independent variable interprets the dependent variable.
In mathematics, R_Squared is given by:
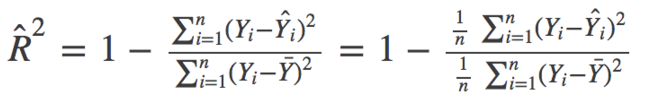
> Wherein the numerator is the MSE (average of residual squares) and the denominator is the variance of the Y value. The higher the MSE, the smaller the R_squared, indicating that the model is worse.
Like R2, the correction R2 also shows the degree of interpretation of the dependent variable by the independent variable, and the regression problem is reflected in the goodness of fit of the curve, but can be adjusted according to the number of independent variables in the model. It is given by the following formula:
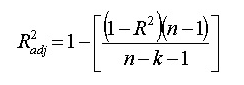
Where n represents the total number of observations and k represents the number of predictions. Corrected R2 is always less than or equal to R2.
Why should you choose R2 over R2?
The standard R2 often has some problems in use, but it can be well solved by using R2. Because the correction R2 will consider adding additional items in the model, resulting in improved performance. If you add useful items, R2 will increase, and if you add less useful predictors, R2 will decrease. However, even if the model does not actually improve, R2 increases with the number of variables. Below we use an example to better understand this.

Here, Case 1 is a very simple case, we have 5 observations (x,y). In case 2, let a variable be twice as variable 1 (that is, it is completely related to variable 1). In case 3, we made a slight disturbance to variable 2 so that it is no longer completely related to variable 1.
So, if we fit each case with a simple, ordinary least squares (OLS) model, logically the information we provided for Case 1, Case 2, and Case 3 is the same, then our Metrics do not improve over these models. However, in reality R2 will give higher values ​​for models 2 and 3, which is obviously incorrect. However, the problem can be solved by correcting R2, which is actually reduced for cases 2 and 3. Let's assign some values ​​to these variables (x, y) and look at the results obtained in Python.
Note: The predicted values ​​for Model 1 and Model 2 will be the same, so R2 will also be the same because it depends only on the predicted and actual values.

From the above table, it can be seen that from Case 1 to Case 3, although we have not added any additional information, R2 is still increasing, and the corrected R2 shows the correct trend (Penalty Model 2 has more variables)
Contrast correction R2 and RMSE
For the previous example, we will see that the RMSE results obtained in Case 1 and Case 2 are similar to R2. In this case, correcting R2 is better than RMSE because it only compares the predicted and actual values. Moreover, the absolute value of RMSE does not really explain how bad the model is; it can only be used to compare two models, but correcting R2 makes this easy to do. For example, if the current R2 of a model is 0.05, then this model is definitely poor.
However, if you only care about prediction accuracy, then RMSE is the best choice. It is simple to calculate and easy to distinguish. It is generally the default measure of most models.
Common misconceptions: I often see online that R2 ranges from 0 to 1, which is not the case. The maximum value of R2 is 1, but the minimum value can be negative infinity. Even if the true value of y is a positive number, the model predicts high negative values ​​for all observations. In this case, R2 will be less than zero. Although this is an unlikely situation, the possibility still exists.
Interesting indicators
There is an interesting indicator here. If you are interested in NLP, Andrew Ng introduced it in the deep learning course. BLEU (Bilingual Evaluation Understudy)
It is mainly used to measure the quality of machine translation in relation to human translation. It uses a modified form of precise measurement.
Steps to calculate the BLEU score:
1. Convert a sentence into a single word, two words, three words, and four words
2. Calculate the accuracy of the n syntax of sizes 1 to 4, respectively
3. Take the weighted average index of all these precision values
4. Multiply it by a short penalty term (explained later)
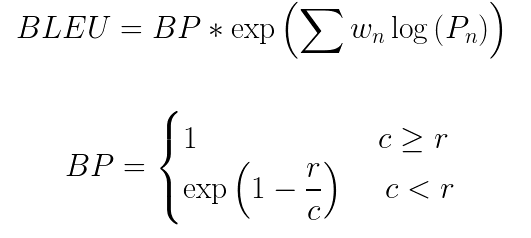
Here BP is a short penalty term, r and c are the number of words in the reference translation and the candidate translation, w is the weight, and P is the precision value.
example:
Reference: The cat is sitting on the mat
Machine Translation 1:On the mat is a cat
Machine Translation 2: There is cat sitting cat
Let's compare the BLEU scores of the above two translations.
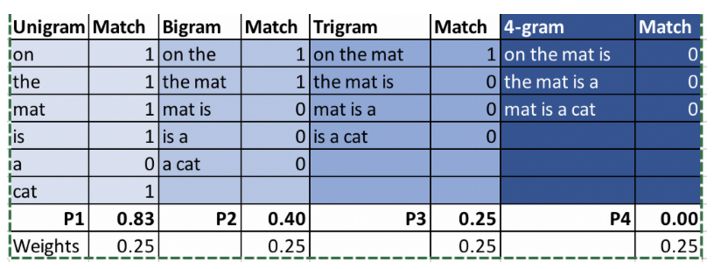
The final result: BLEU (MT1) = 0.454, BLEU (MT2) = 0.59
Why introduce a simple penalty item?
The penalties introduced will punish candidate translations that are shorter than the reference translation. For example, if the reference translation for the above-mentioned candidate translation is "The cat", then it will have a very high precision for a single word and two words because both words appear in the reference translation in the same order. However, if the length is too short, it does not actually reflect the meaning of the reference translation. With this brief penalty, candidate translations must match the reference translation in terms of length, the same word, and word order to get high scores.
It is hoped that through the introduction of this article, we can understand the differences between different metrics, and can select suitable model metrics for machine learning, evaluate the quality of modeling, and guide the optimization of models.
Solid-state Capacitors / Motor Starting Capacitors
Solid - state capacitors are all called: solid - state Aluminum Electrolytic Capacitors.It with the ordinary capacitance (that is, the liquid aluminum electrolytic capacitors) the biggest difference is that use different dielectric material, liquid aluminum capacitor dielectric material as the electrolyte, and solid-state capacitor dielectric material is conductive polymer materials.Solid-state capacitors / Motor starting capacitors
Solid-state capacitors,Motor starting capacitors,Solid-State Capacitors,Solid-State Small Size Capacitors,Solid-State Low Impedance Capacitors,Long Life Solid-State Capacitors
YANGZHOU POSITIONING TECH CO., LTD. , https://www.cnpositioning.com